Study BCR-ABL prediction from gene-expression profiles and evaluate how PB inference methods calibrate downstream inference in genomics.
Background & Motivation
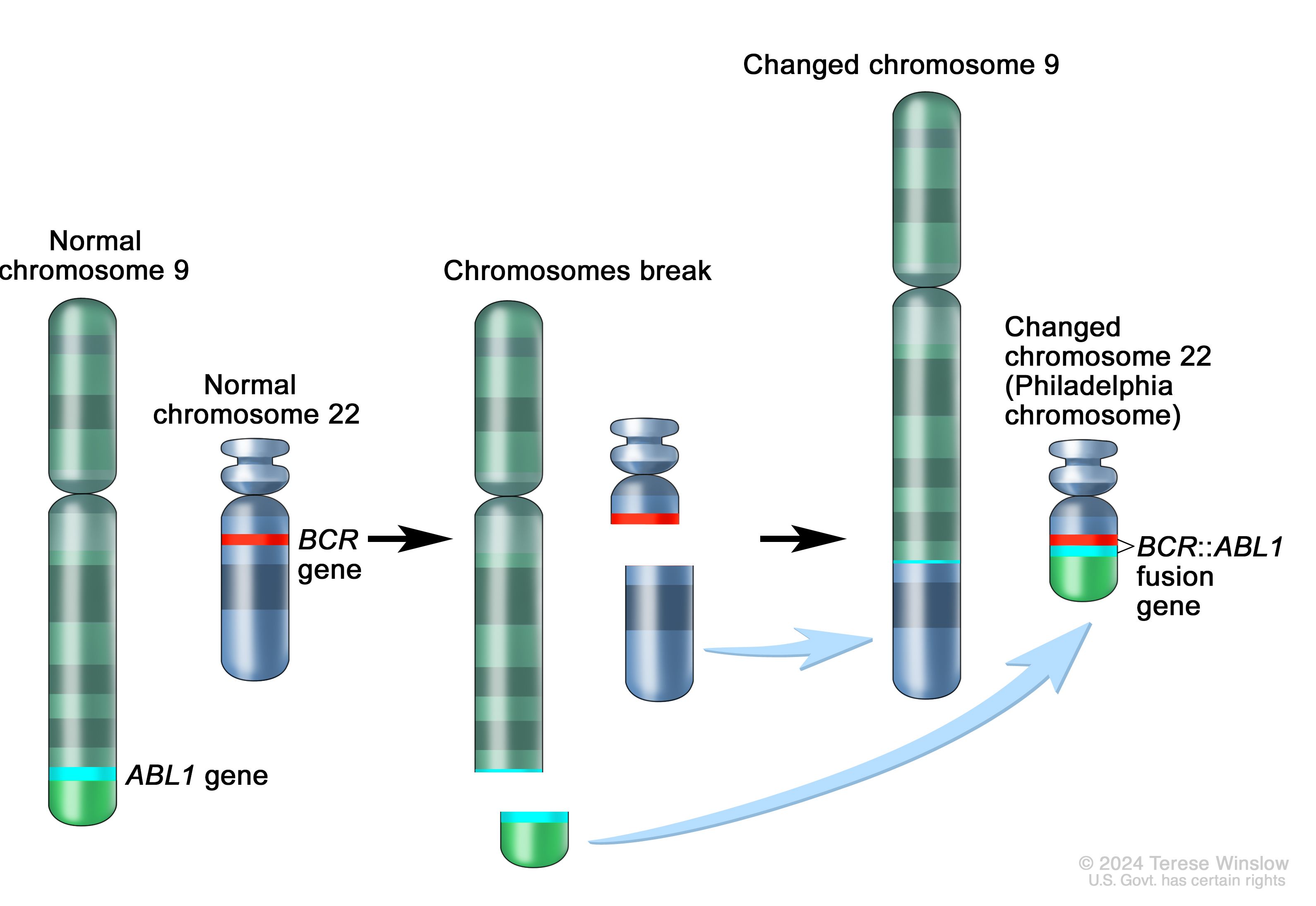
Acute lymphoblastic leukemia (ALL) is the most common childhood cancer, but it exhibits marked genetic heterogeneity, with distinct chromosomal translocations defining molecular subtypes with divergent prognoses and therapeutic responses. In B-cell lineage ALL, the BCR-ABL1 fusion (“breakpoint cluster region”/“Abelson”, i.e., the “Philadelphia chromosome”) arises from a t(9;22) translocation and encodes a constitutively active tyrosine kinase. This fusion was historically associated with poor outcomes, until the advent of targeted therapies (e.g., imatinib) revolutionized treatment and survival.
High-density microarray profiling measures expression of over 7,000 genes in leukemic blast cells, enabling a form of “molecular diagnostics” where supervised learning can:
Classify fusion status or other genetic subtypes when cytogenetic assays (PCR, FISH) are unavailable.
Discover novel marker genes and pathways dysregulated by specific fusions.
Predict therapeutic response and stratify risk using expression-derived scores.
However, in many retrospective or multi-center cohorts, only a subset of patients undergo gold-standard fusion testing (e.g., RT-PCR for BCR-ABL1), leaving the majority “unlabeled.” A common workaround is to train a gene expression classifier on the small labeled subset and apply it to the larger unlabeled cohort. Yet, naive downstream analyses, treating predicted labels as ground truth, can yield biased effect estimates and understate uncertainty.
Prediction-based (PB) inference methods offer a principled remedy: combine a small labeled set with the predicted labels (e.g., with true fusion status) with a larger unlabeled set, adjusting both bias and variance. In this module, we will:
Subset the ALL data to B-cell ALL and filter to the top 500 variable probes.
Harmonize probes across platforms via gene symbols.
Split the ALL data and train three classifiers for BCR-ABL1 fusion status.
Predict on the holdout ALL and Golub B-cell ALL data using the ALL-trained classifier.
Apply PB inference to estimate the association between fusion status and patient sex assigned at birth.
By the end, you will understand how to leverage expression-based predictions while maintaining valid inference on genetic subtypes in cohorts with partially missing gold-standard labels.
Note: For the data loading and prediction workflows, we will directly follow the Bioconductor MLInterfaces vignette by VJ Carey and P Atieno:
ALL (ALL package): 128 samples of acute lymphoblastic leukemia (both B- and T-cell), profiled on the Affymetrix HGU95Av2 microarray. Phenotype data include BT (immunophenotype), mol.biol (molecular subtype including BCR-ABL1 or NEG), age, and sex.
Golub_Merge (golubEsets package): 72 samples of leukemias (ALL vs. AML), profiled on Affymetrix HGU6800. Phenotype data include ALL.AML, T.B.cell (lineage), age, and sex.
We will train our classifiers on a subset of the ALL data, test the model on the holdout ALL data, and perform PB inference on the holdout ALL and Golub data.
Phenotype Reduction and Feature Filtering
We first narrow to B-cell ALL samples and reduce dimensionality by keeping the 500 most variable probes.
# Load the ALL datadata(ALL)# Subset ALL to B-cell lineage (BT codes starting with "B")bALL <- ALL[, substr(pData(ALL)$BT, 1, 1) =="B"]# Keep only fusion-negative ("NEG") and fusion-positive ("BCR/ABL") samplesfus <- bALL[, bALL$mol.biol %in%c("NEG", "BCR/ABL")]# Convert to factor with clear levels: NEG=0, BCR/ABL=1fus$mol.biol <-factor(fus$mol.biol, levels =c("NEG", "BCR/ABL"))# Compute median absolute deviation (MAD) for each probedevs <-apply(exprs(fus), 1, mad)# Select top 500 most variable probes by MAD rankingtop500 <-order(devs, decreasing =TRUE)[1:500]# Subset ExpressionSet to top 500 probesdat_filt <- fus[top500, ]# Confirm dimensions: 500 probes x n samplesdim(exprs(dat_filt))
[1] 500 79
Explanation:
mad() is robust to outliers and captures variability.
Filtering saves time on downstream analysis without losing key signals.
We now have dat_filt, a filtered ALL dataset focused on B-cell lineage and the most informative probes.
Cross-Platform Probe Harmonization
To predict on the Golub data, which uses a different array, we map probes from each platform to gene symbols, then intersect to find a common gene set.
# Load the Golub datadata(Golub_Merge)# Map HGU95Av2 probes (ALL) to gene symbolsgmap_all <- AnnotationDbi::select( hgu95av2.db,keys =featureNames(dat_filt),columns =c("PROBEID","SYMBOL"),keytype ="PROBEID")# HGU6800 probes (Golub) to gene symbolsgmap_golub <- AnnotationDbi::select( hu6800.db,keys =featureNames(Golub_Merge),columns =c("PROBEID","SYMBOL"),keytype ="PROBEID")# Identify common symbolscommon_sym <-intersect(gmap_all$SYMBOL, gmap_golub$SYMBOL)# For each symbol, pick the first associated probeprobe_all <- gmap_all |>filter(SYMBOL %in% common_sym) |>group_by(SYMBOL) |> dplyr::slice(1) |>drop_na()probe_golub <- gmap_golub |>filter(SYMBOL %in% common_sym) |>group_by(SYMBOL) |> dplyr::slice(1) |>drop_na()# Subset ExpressionSets to these probesdat_train <- dat_filt[probe_all$PROBEID, ]eset_golub <- Golub_Merge[probe_golub$PROBEID, ]# Further subset Golub to B-cell ALL samplesgolub_bALL <- eset_golub[, pData(eset_golub)$T.B.cell =="B-cell"&pData(eset_golub)$ALL.AML =="ALL"]featureNames(dat_train) <- probe_all$SYMBOLrownames(exprs(dat_train)) <- probe_all$SYMBOLfeatureNames(golub_bALL) <- probe_golub$SYMBOLrownames(exprs(golub_bALL)) <- probe_golub$SYMBOL# Confirm feature dimensionsdim(dat_train) # features x ALL samples
Features Samples
354 79
dim(golub_bALL) # features x Golub B-cell ALL samples
Features Samples
354 38
dat_train and golub_BALL now share the same gene-symbol feature set, ready for model training and transfer.
Exploratory Data Analysis
With our filtered training set (dat_train), we explore patterns using a heatmap and principal component analysis (PCA).
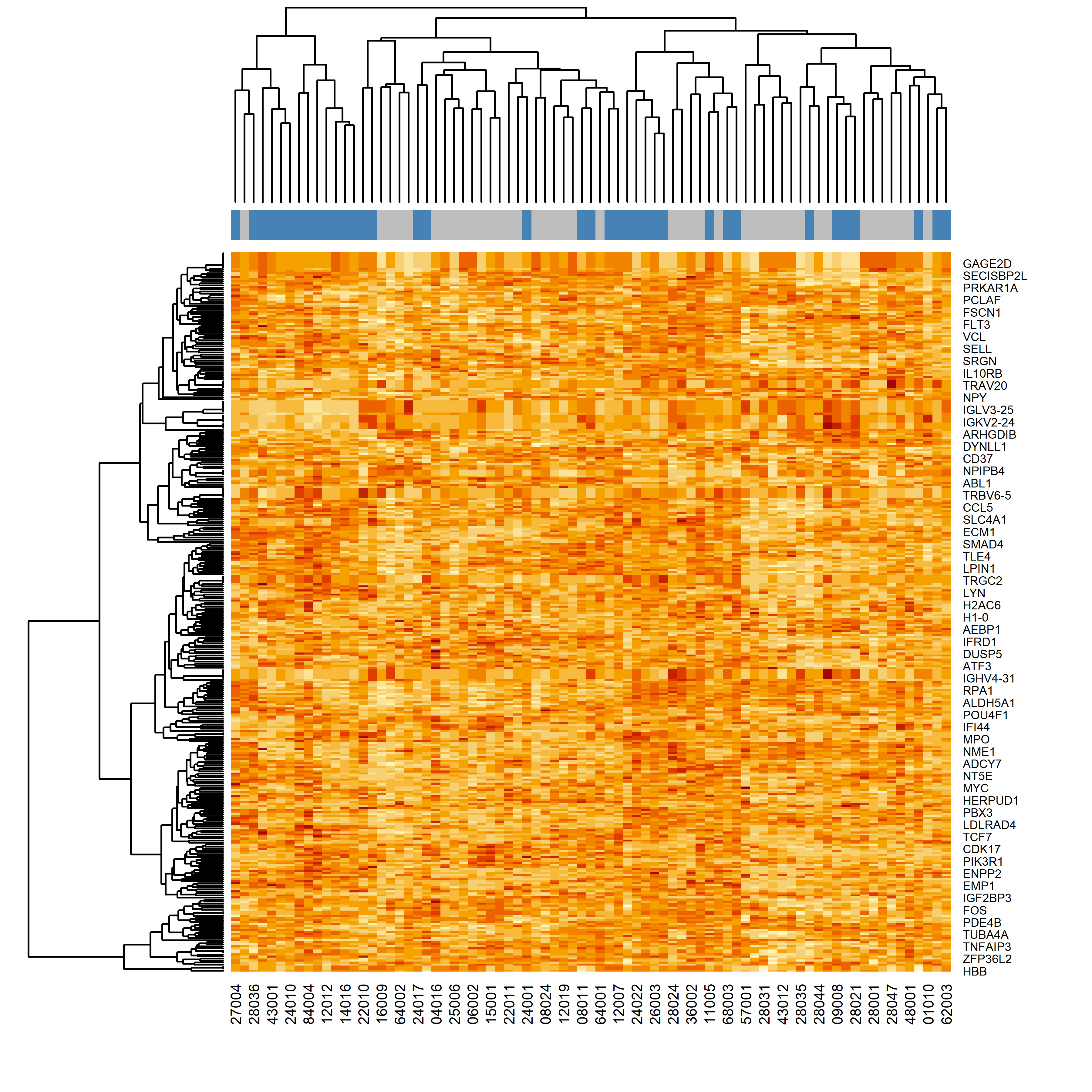
# Set subtype colors for visualizationfcol <-ifelse(dat_train$mol.biol =="NEG", "gray", "steelblue")heatmap(exprs(dat_train), ColSideColors = fcol)
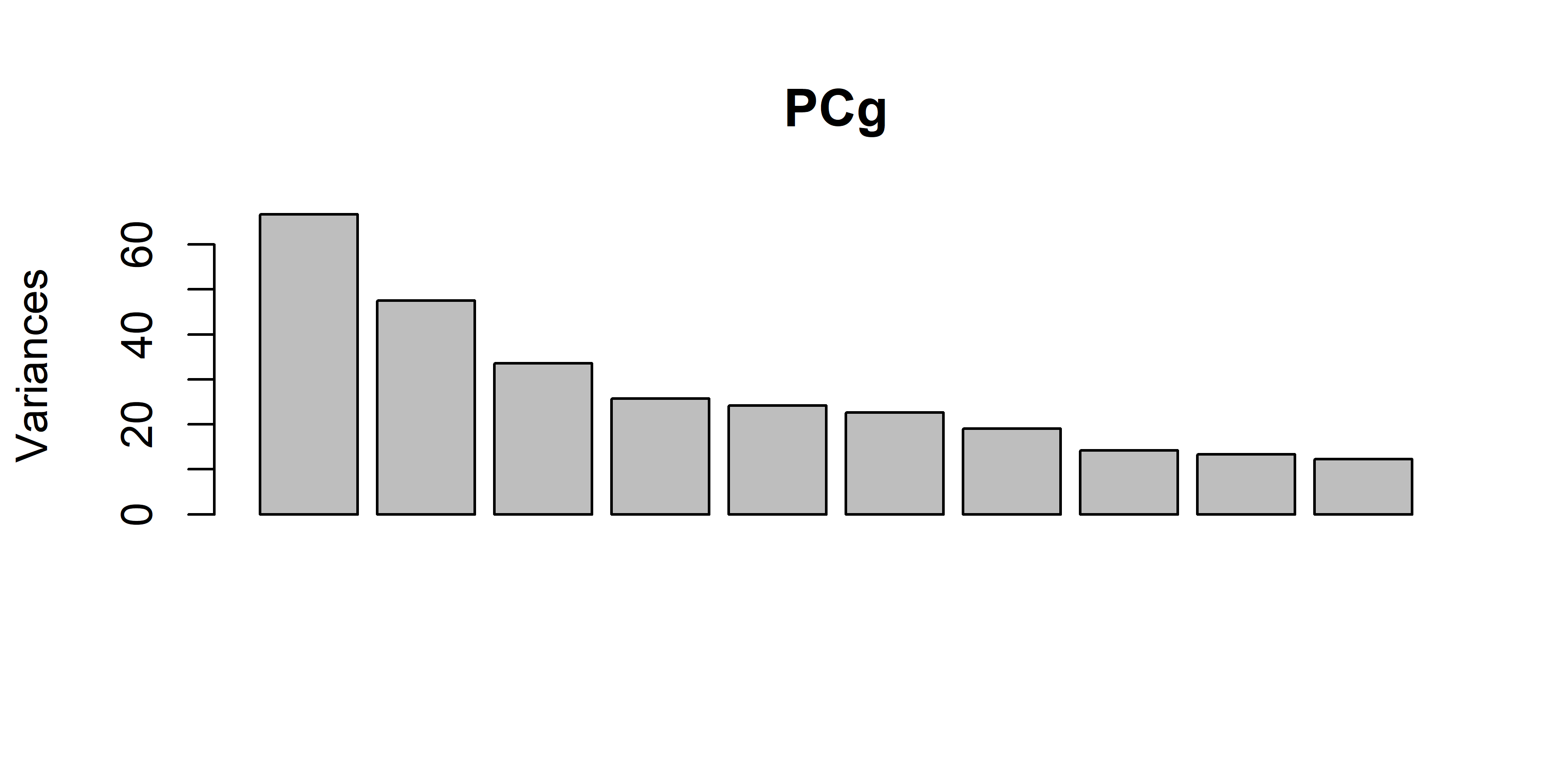
# PCA on samplesPCg <-prcomp(t(exprs(dat_train)))# Scree plotplot(PCg)
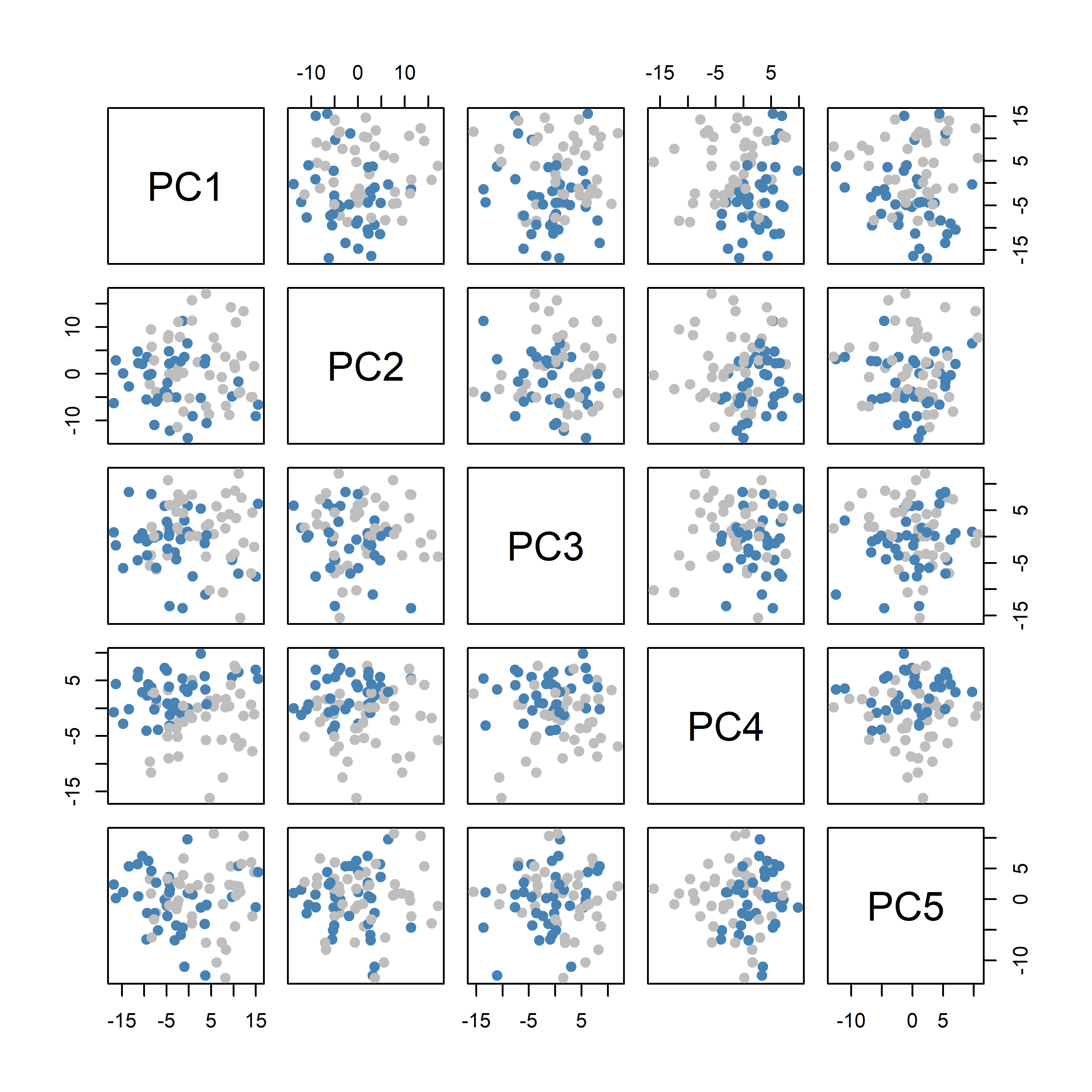
# Scatterplots of PCspairs(PCg$x[, 1:5], col = fcol, pch =19)
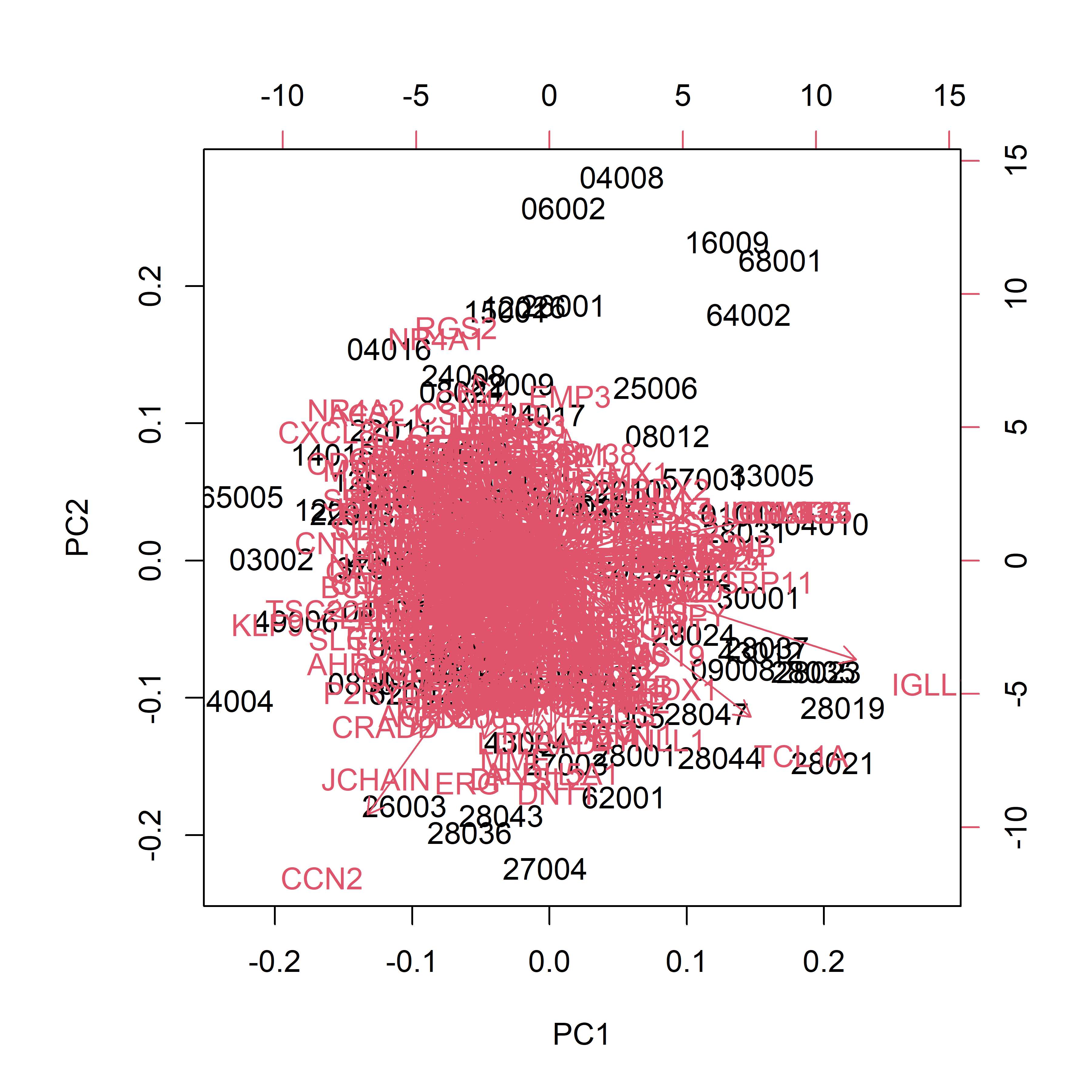
# Biplot of PC1 vs PC2biplot(PCg)
Interpretation:
The heatmap reveals distinct blocks of probes whose expression differs between BCR-ABL1 fusion-positive and fusion-negative samples.
The PCA scatter shows separation (or overlap) of samples by fusion status along the first two principal components, and to a lesser extent, the next three.
In the biplot, probes lying far from the origin along PC1 or PC2 represent genes with the largest loadings, i.e., the greatest contribution to those principal components. Samples positioned similarly share expression patterns in those genes.
Overall, the modest separation in PCA indicates the need for supervised methods to pinpoint the genes most predictive of BCR-ABL1 status.
Train/Test Split and Classifier Training
We split dat_train (ALL) into 60% training and 40% holdout, then train three ML models.
set.seed(2025) # for reproducibilityn_all <-ncol(dat_train) # number of ALL samplestrain_idx <-sample(n_all, size =floor(0.6* n_all))# Training and holdout ExpressionSetstrain_eset <- dat_train[, train_idx]test_eset <- dat_train[, -train_idx]
In this section, we compare three supervised learning methods using the MLInterfaces framework:
Diagonal Linear Discriminant Analysis (dldaI)
Neural Network (nnetI)
Random Forest (randomForestI)
We will use the MLearn() function, which wraps each algorithm, providing a consistent interface to train, predict, and evaluate models on an ExpressionSet. After fitting, we will use confuMat() to display the confusion matrix, showing the true versus predicted class counts.
We train each model on the first 40 most variable probes from the filtered ExpressionSet (features 1:40 in train_eset).
Diagonal Linear Discriminant Analysis (dldaI)
Diagonal LDA assumes each feature is conditionally independent (covariance matrix is diagonal), which can improve stability in high-dimensional, low-sample settings. We use the dldaI interface to fit and evaluate this classifier.
# Train Diagonal LDA on probes 1:40dlda_mod <-MLearn( mol.biol ~ ., # mol.biol ~ . specifies BCR/ABL1 fusion status as the outcome train_eset, # Filtered ExpressionSet dldaI, # dldaI is the diagonal LDA interface1:40# 1:40 selects the first 40 probes)
[1] "mol.biol"
# Print a summary of the fitted modeldlda_mod
MLInterfaces classification output container
The call was:
MLearn(formula = mol.biol ~ ., data = train_eset, .method = dldaI,
trainInd = 1:40)
Predicted outcome distribution for test set:
BCR/ABL NEG
3 4
# Display the confusion matrix (true vs predicted)cm_dlda <-confuMat(dlda_mod)cm_dlda
predicted
given BCR/ABL NEG
BCR/ABL 3 1
NEG 0 3
# Accuracy of Diagonal LDAacc_dlda <-sum(diag(cm_dlda)) /sum(cm_dlda)cat("Accuracy:", sprintf("%.2f%%", acc_dlda *100))
Accuracy: 85.71%
Neural Network (nnetI)
A single hidden layer neural network can capture non-linear relationships. We use the nnetI interface with default parameters plus:
[1] "mol.biol"
# weights: 1781
initial value 31.210991
iter 10 value 19.645950
iter 20 value 12.779243
iter 30 value 5.459003
iter 40 value 1.841191
iter 50 value 1.334631
iter 60 value 1.133200
iter 70 value 0.875814
iter 80 value 0.704137
iter 90 value 0.625722
iter 100 value 0.610470
final value 0.610470
stopped after 100 iterations
# Show model summarynn_mod
MLInterfaces classification output container
The call was:
MLearn(formula = mol.biol ~ ., data = train_eset, .method = nnetI,
trainInd = 1:40, size = 5, decay = 0.01, MaxNWts = 2000)
Predicted outcome distribution for test set:
BCR/ABL NEG
5 2
Summary of scores on test set (use testScores() method for details):
[1] 0.2948988
# Confusion matrix for Neural Netcm_nn <-confuMat(nn_mod)cm_nn
predicted
given BCR/ABL NEG
BCR/ABL 4 0
NEG 1 2
# Accuracy of Neural Netacc_nn <-sum(diag(cm_nn)) /sum(cm_nn)cat("Accuracy:", sprintf("%.2f%%", acc_nn *100))
Accuracy: 85.71%
Random Forest (randomForestI)
Random forests build an ensemble of decision trees on bootstrapped samples and random feature subsets, offering robust performance with little tuning. We use the randomForestI to fit a random forest model:
MLInterfaces classification output container
The call was:
MLearn(formula = mol.biol ~ ., data = train_eset, .method = randomForestI,
trainInd = 1:40)
Predicted outcome distribution for test set:
BCR/ABL NEG
4 3
Summary of scores on test set (use testScores() method for details):
BCR/ABL NEG
0.524 0.476
# Confusion matrixcm_rf <-confuMat(rf_mod)cm_rf
predicted
given BCR/ABL NEG
BCR/ABL 4 0
NEG 0 3
# Accuracy of Random Forestacc_rf <-sum(diag(cm_rf)) /sum(cm_rf)cat("Accuracy:", sprintf("%.2f%%", acc_rf *100))
Accuracy: 100.00%
Interpretation: Only the Random Forest achieves perfect separation in the validation samples. This highlights the challenge of discriminating BCR-ABL1 status based solely on the top variable probes and underscores why downstream PB inference corrections (for regression inference) remain valuable.
Predictions on ALL Test and Golub
After fitting our classifiers on the training subset of ALL, we now generate predictions on both the ALL holdout test and the Golub B-cell ALL datasets.
# Predict BCR-ABL1 status on ALL test holdout using random forestall_pred <- MLInterfaces::predict.classifierOutput(rf_mod, test_eset)# Compare to true labels in test_esetconf_mat_test <-table(Truth = test_eset$mol.biol,Predicted= all_pred$testPredictions)conf_mat_test
Predicted
Truth BCR/ABL NEG
NEG 3 16
BCR/ABL 11 2
# Predict BCR-ABL1 status on Golub B-cell ALLgolub_pred <- MLInterfaces::predict.classifierOutput(rf_mod, golub_bALL)# Summarize prediction counts (no ground truth in Golub)table(golub_pred$testPredictions)
BCR/ABL NEG
25 13
Note: We retain true labels in the ALL test set for later PB inference; Golub remains unlabeled.
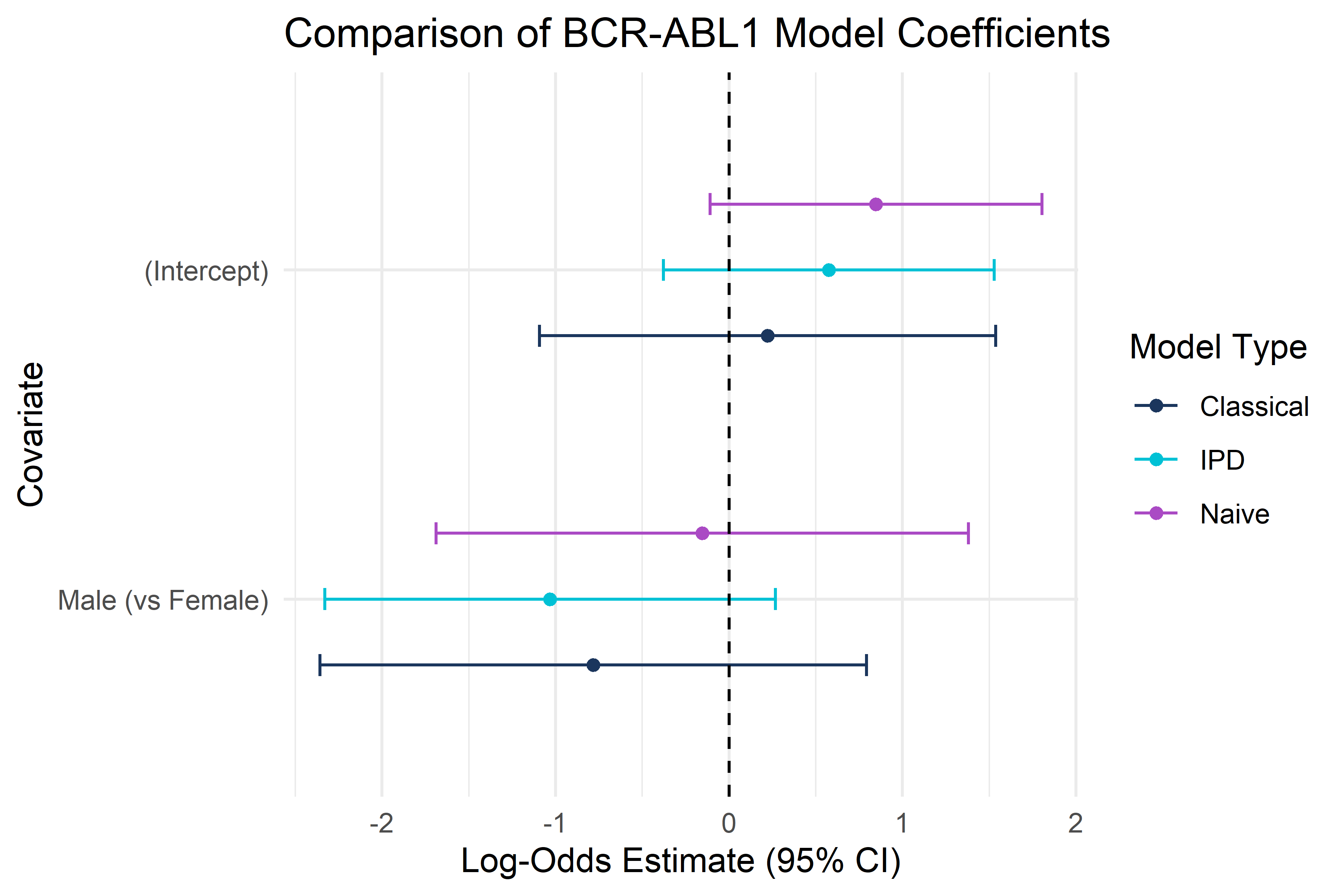
PB Inference on Sex Effect
We will now use PB Inference to estimate the log-odds effect of sex (male vs female) on true BCR-ABL1 status, combining the holdout ALL data with true and predict fusion status (i.e., our labeled data) and the Golub data with the predicted fusion status (i.e., our unlabeled data)
Insight: By treating the ALL test set as labeled and Golub as unlabeled, PB inference combines information across cohorts to correct bias and improve precision when estimating the association between BCR-ABL1 status and patient sex.
This is the end of the module. We hope this was informative! For question/concerns/suggestions, please reach out to ssalerno@fredhutch.org